要使用Python爬虫获取福彩双色球的历史数据,你可以按照以下步骤进行:
1. "确定数据源":首先需要找到提供福彩双色球历史数据的网站。
2. "分析网页结构":使用开发者工具分析网页的HTML结构,找到历史数据所在的表格或列表。
3. "编写爬虫代码":使用Python的requests库获取网页内容,然后用BeautifulSoup或lxml解析HTML,提取所需的数据。
4. "数据存储":将提取的数据保存到CSV文件或数据库中。
以下是一个简单的示例代码,它演示了如何使用requests和BeautifulSoup从某个假设的福彩双色球数据网站获取数据:
```python
import requests
from bs4 import BeautifulSoup
import csv
# 假设这是福彩双色球历史数据的URL
url = 'http://www.example.com/lottery/slt/history'
# 发送HTTP请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 假设历史数据在表格中,且表格的class为'history-table'
table = soup.find('table', class_='history-table')
# 提取表格中的所有行
rows = table.find_all('tr')
# 创建CSV文件并写入标题行
相关内容:
以下是使用Python爬虫获取福彩历史数据的步骤和示例代码。以中国福彩双色球历史数据为例,假设目标数据可通过官方网站或第三方公开数据接口获取。
步骤 1:分析目标数据源
假设目标数据来自中国福彩官网或第三方数据网站(如500彩票网),需检查:
1. 网站是否有反爬机制(如IP限制、验证码)。
2. 数据是否通过HTML直接渲染或动态加载(如Ajax请求)。
3. 确认robots.txt是否允许爬取。
步骤 2:获取数据接口
通过浏览器开发者工具(Network选项卡)分析数据加载方式。若数据通过Ajax接口返回JSON,则直接调用API更高效。例如,500彩票网的双色球历史数据接口可能类似:

示例代码(静态页面爬取)
若数据在静态HTML表格中,使用requests和BeautifulSoup解析。
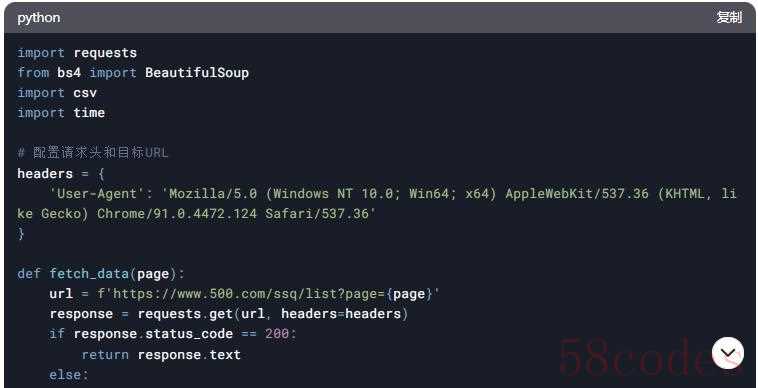
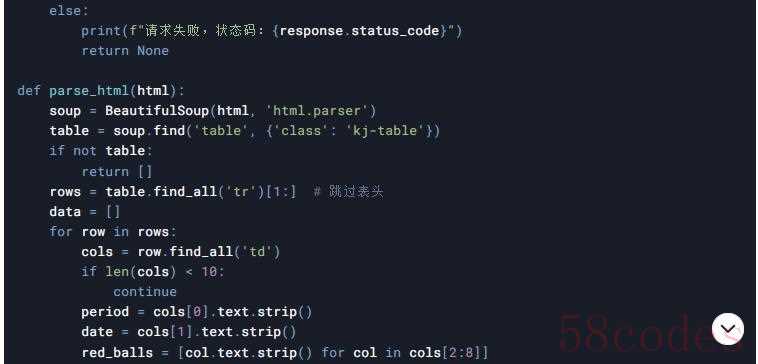
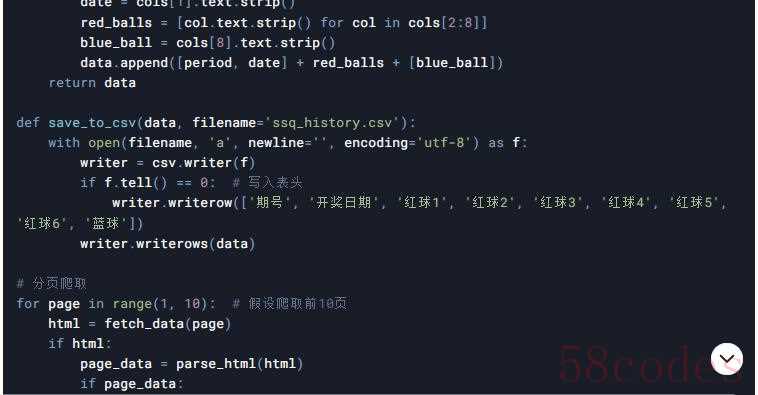

示例代码(动态API接口)
若数据通过Ajax接口返回JSON:
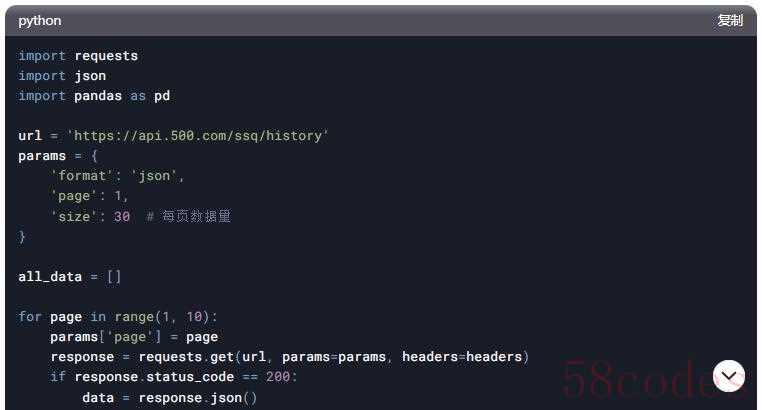
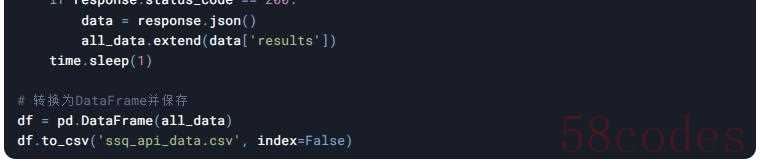
注意事项
1. 合法合规:确保遵守目标网站的robots.txt和服务条款,避免高频访问。
2. 反爬策略:
o 使用随机User-Agent(可借助fake_useragent库)。
o 设置请求间隔(如time.sleep(2))。
o 使用代理IP池(如requests结合proxies参数)。
3. 异常处理:增加try-except块处理网络错误或数据解析失败。
4. 数据清洗:检查数据完整性(如缺失值、格式错误)。
扩展建议
• 数据存储:可改用数据库(如SQLite、MySQL)长期存储。
• 定时任务:使用APScheduler或crontab定期更新数据。
• 可视化:用matplotlib或pandas分析历史趋势。
希望以上内容对您有所帮助!

 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
