不正确使用爬虫容易被抓,主要是由于以下几个原因:
1. "频繁请求":如果爬虫对目标网站发送请求过于频繁,网站可能会认为这是恶意行为,从而采取措施阻止爬虫的进一步访问。这种情况下,网站可能会对爬虫的IP地址进行封禁。
2. "不模拟正常用户行为":正常用户在浏览网站时,会进行点击、滚动等操作,并花费一定的时间。而一些爬虫可能会一次性加载大量页面,或者不进行任何模拟用户行为的操作,这种行为很容易被网站识别为爬虫。
3. "不遵守网站的robots.txt文件":网站通常会提供一个robots.txt文件,用于指定哪些页面可以被抓取,哪些页面不可以。如果爬虫不遵守这个文件,可能会被网站封禁。
4. "不设置合适的User-Agent":User-Agent是浏览器向服务器发送请求时,用来标识自己的标识符。如果爬虫不设置合适的User-Agent,网站可能会认为这是恶意行为。
5. "不处理异常情况":在爬取过程中,可能会遇到各种异常情况,如网络连接超时、页面解析错误等。如果爬虫不处理这些异常情况,可能会被网站识别为恶意行为。
6. "不进行IP代理的切换":如果爬虫使用同一个IP地址发送大量请求,很容易被网站封禁。因此,在进行大规模爬取时,应该使用IP代理进行切换。
7.
相关内容:
打开购物软件时,你有没有好奇过,那些自动汇总的 "全网最低价" 是怎么来的?刷新闻时,APP 精准推送的 "你可能感兴趣" 又依赖什么技术?这些背后,可能都藏着一个叫 "爬虫" 的工具。但这两年,"某公司因爬虫被起诉"" 程序员爬数据获刑 " 的新闻越来越多 —— 爬虫到底是啥?为啥一不小心就会触犯法律?

一、爬虫技术:网络世界的 "自动抄书员"
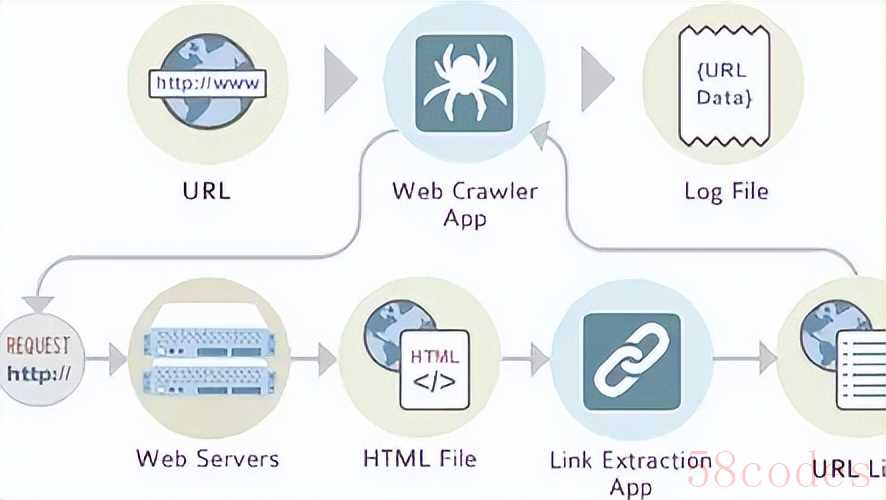
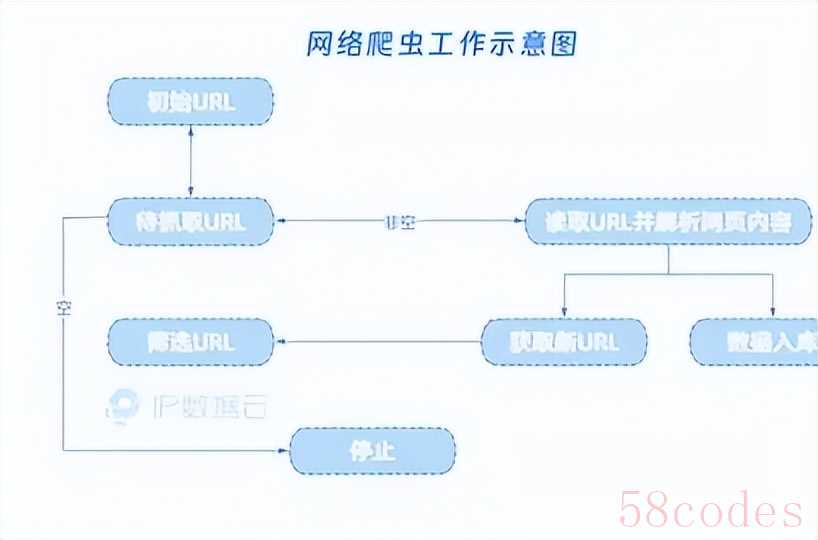
简单说,爬虫技术就是一种能自动抓取网络信息的程序,有点像个不知疲倦的 "网络抄书员"。我们手动打开网页、复制粘贴信息的过程,爬虫能通过代码自动完成:它会按照设定的规则,向目标网站发送访问请求,拿到网页数据后,自动提取有用信息(比如商品价格、新闻标题),最后整理成表格、数据库等方便使用的形式。
从技术角度看,爬虫的工作流程不复杂:首先通过 HTTP 协议向网站服务器 "要数据",服务器返回 HTML、JSON 等格式的内容后,爬虫用解析工具(比如 Python 的 BeautifulSoup 库)提取关键信息,再把结果存到本地或云端。就像我们用浏览器上网一样,只不过爬虫把 "人点鼠标" 变成了 "代码自动操作"。
日常中,爬虫的应用其实很常见:搜索引擎靠爬虫收录全网页面,否则我们搜不到任何结果;天气 APP 用爬虫汇总各地气象数据;甚至学术研究中,研究者也会用爬虫收集公开论文数据做分析。可以说,没有爬虫,互联网的 "信息流通" 会慢很多。
二、爬虫惹麻烦?多半是踩了这几条红线
爬虫本身是中性的技术,但这两年相关法律纠纷越来越多,核心原因是:很多人用爬虫时,越过了 "合法边界"。具体来说,容易踩坑的情况主要有三种。
第一,爬了法律明确保护的数据。 最典型的是个人信息和商业秘密。比如有公司爬取招聘网站上的简历,获取求职者的手机号、身份证号,哪怕这些信息是 "公开可查" 的,也可能违反《个人信息保护法》—— 因为法律规定,处理个人信息需要 "合法、正当、必要",大规模爬取并用于盈利,显然超出了 "必要" 范围。
商业秘密更敏感。比如某餐饮平台的菜品销量、用户评价,这些数据是平台投入成本积累的,属于 "具有商业价值的未公开信息"。如果另一家公司用爬虫批量抓取,再直接放到自己平台上,就可能构成《反不正当竞争法》里的 "不正当竞争"。2016 年 "大众点评诉百度地图" 案中,法院就认为百度爬虫抓取大众点评的商户评价并展示,属于 "搭便车",最终判百度侵权。

第二,爬取方式干扰了网站正常运营。 有些爬虫为了快速获取数据,会用 "高频访问" 的方式轰炸网站 —— 比如一秒钟发送几十次请求,这会导致网站服务器过载、卡顿甚至崩溃。这种行为可能违反《网络安全法》,被认定为 "危害网络安全的活动"。2021 年,某公司因爬虫爬取某电商平台数据时,每秒发送上百次请求导致平台瘫痪,最终被罚款 200 万元。
还有些爬虫会 "耍手段":比如绕开网站的反爬措施(像验证码、IP 封锁),甚至破解网站的登录权限,爬取需要付费或登录才能查看的内容。这种 "突破技术限制" 的行为,可能触犯《刑法》第 285 条,构成 "非法获取计算机信息系统数据罪",最高可判 7 年有期徒刑。

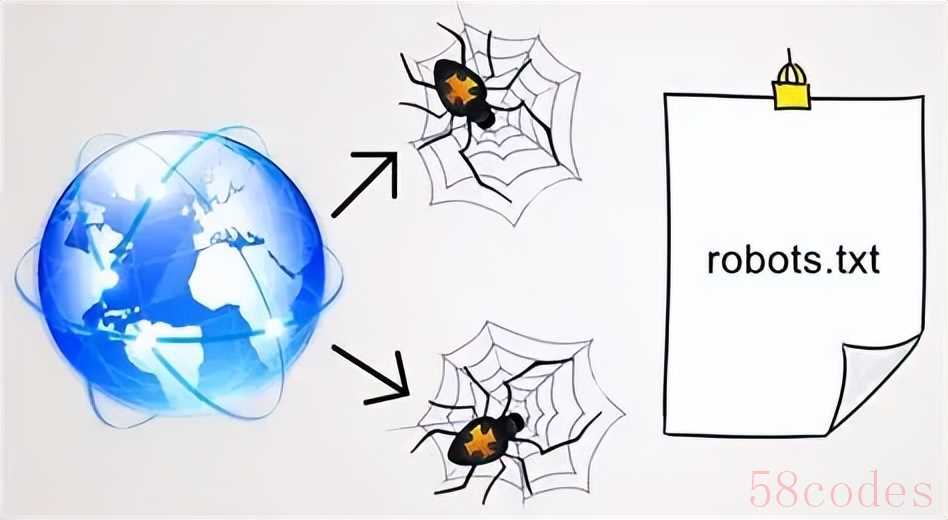
第三,忽视了 "君子协议"robots 协议。 很多网站会在根目录放一个 "robots.txt" 文件,明确告诉爬虫 "哪些内容可以爬,哪些不能爬"。比如知乎的 robots 协议会禁止爬虫抓取用户私信,豆瓣会限制爬虫访问小组内容。虽然 robots 协议不是法律,但法院在判决时往往会参考 —— 如果明明看到协议禁止,还非要爬,就可能被认定为 "主观恶意",加重责任。2020 年 "淘宝诉美景公司" 案中,法院就认为美景公司无视 robots 协议爬取淘宝数据,构成不正当竞争。
三、法律红线划在哪?这几个边界要记牢
想用好爬虫,关键是搞懂法律的 "禁区" 在哪。结合现行法律和司法案例,有三个边界必须明确。
首先,"公开可查"≠"可以随便爬"。 路边的广告牌信息公开,但你不能把全城广告牌都拍下来做成数据库卖钱 —— 网络数据也是一个道理。哪怕是公开在网页上的信息,大规模爬取、商用也可能违法,尤其是当这些数据是网站的 "核心资产" 时(比如点评网站的用户评价、旅游网站的机票价格)。
其次,个人信息绝对碰不得。 《个人信息保护法》实施后,这个边界越来越清晰:只要涉及 "识别特定个人" 的信息(手机号、邮箱、住址、消费记录等),哪怕是用户自己公开的,爬虫也不能随意抓取。2023 年,某社交 APP 因爬取用户头像、昵称并用于商业推广,被法院判决赔偿,就是因为这些信息虽然 "公开",但属于受保护的个人信息。
最后,爬取行为不能 "扰邻"。 就像你不能半夜砸邻居家门一样,爬虫也不能干扰网站的正常运行。比如用 "分布式爬虫" 同时从成千上万个 IP 地址发起请求,或者爬取速度远超网站承受能力,导致服务器瘫痪,这就可能构成《治安管理处罚法》里的 "扰乱公共秩序",甚至触犯刑法。
四、想合法用爬虫?这几步不能少
如果确实需要用爬虫获取数据,做好这几点能大幅降低风险:
先看 robots 协议。访问目标网站的 "robots.txt"(比如
www.example.com/robots.txt),明确禁止爬取的内容坚决不碰;
控制爬取速度。把请求间隔设得长一点(比如每秒不超过 1 次),避免给服务器添负担;
不碰敏感数据。个人信息、加密内容、需要付费 / 登录才能看的内容,一律不爬;
最好提前沟通。如果是商用,尽量联系网站方获取授权,哪怕只是一封确认邮件,也能成为合法依据;
关键时刻找律师。涉及大规模数据爬取时,先让法律专业人士评估风险,别等被告了才后悔。
爬虫技术就像一把刀:厨师用它切菜是创造价值,歹徒用它伤人就是犯罪。它本身没有对错,关键在于使用者是否守住法律和道德的边界。毕竟,互联网的便利来自信息流通,但流通的前提,是对他人权利的尊重。
注:图像来源于网络,如有侵权请联系删除
参考资料
- 《中华人民共和国网络安全法》(2017 年实施)
- 《中华人民共和国个人信息保护法》(2021 年实施)
- 最高人民法院《关于审理侵害信息网络传播权民事纠纷案件适用法律若干问题的规定》
- (2016)沪 01 民终 1909 号民事判决书(大众点评诉百度地图不正当竞争案)
- 中国法院网《爬虫技术的法律边界与风险防范》(2023 年)
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏
